")

Definition of Frequent Item-sets
A set of items that appears in many baskets is said to be “frequent.” To be formal, we assume there is a number s, called the support threshold. If I is a set of items, the support for I is the number of baskets for which I is a subset. We say I is frequent if its support is s or more.
Let’s consider a simple example. Consider the transactions for the following items

Next consider the rule that item/itemset is frequently purchased if it occurs at least 50% of the times. So here it should be bought at least 2 times.
For simplicity, let’s abbreviate the items as follows;
Apple-A
Mango-M
Pears-P
Cabbage-Ca
Carrots-Cr
So the table now becomes
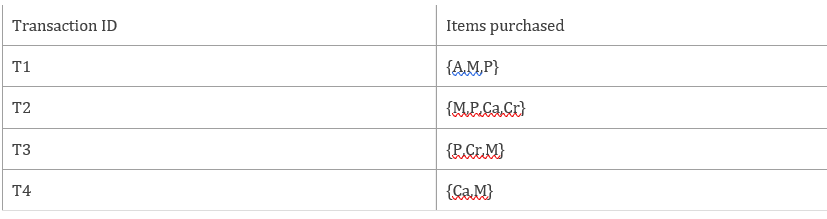
Step 1: Count the number of transactions in which each item occurs

Step 2: Now remove all the items that are purchased less than 2 times. So the new table becomes

Step 3: Start making pairs of the items from step 2 with each other

Note: Itemset PM,CaP, CrP are the same as MP, PCa,PCr so they are not included in step 3.
Step 4: Now we count how many times each pair as shown in Step 3 occurs in Table 1.

Step 5: Look at the question- it states that consider the itemset that is purchased at least 2 times or 50% of the times.
Applying this rule on Step 4 will reduce the table to the following;

So this table shows that the following items MP (Mango and Pears), MCa (Mango and Cabbage) and MCr (Mango and Carrots) are purchased together at least 50% of the times.
Step 1: Load the necessary packages.

First, we will load the packages required for our program.
- Arules – Provides the infrastructure for representing, manipulating and analyzing transaction data and patterns (frequent itemsets and association rules).
- ArulesViz — Implements several known and novel visualization techniques to explore association rules.
- Datasets — This package contains a variety of datasets.
Step 2: Read the Groceries Dataset

Step 3: Now, Let’s take a look at top 10 items from our dataset


Step 4: The final step is to generate the rules with the corresponding support and confidence using the Apriori Algorithm in Arules library
Input:-

Output:-

Step 5: Now remove the redundant rules present in the dataset
Input:-

Output:-

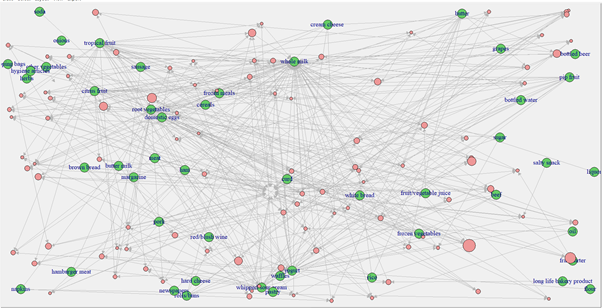
Step 6: Finally display the graph for the Market basket analysis / Association Rules.
Click here to download the Program and Datasets…

