")
Problem Statement- Implement the K-Means algorithm for clustering to create a Cluster on the given data. (Using Python) (Datasets — iris, wine, breast-cancer)
Link to the program and Datasets is given below
K-Means Clustering is an unsupervised machine learning algorithm which basically means we will just have input, not the corresponding output label. In this article, we will see it’s implementation using python.
K Means Clustering tries to cluster your data into clusters based on their similarity. In this algorithm, we have to specify the number of clusters (which is a hyperparameter) we want the data to be grouped into. Hyperparameters are the variables whose value need to be set before applying value to the dataset. Hyperparameters are adjustable parameters you choose to train a model that carries out the training process itself.
Working of K- Means Algorithm
To process the learning data, the K-means algorithm in data mining starts with the first group of randomly selected centroids, which are used as the beginning points for every cluster, and then performs iterative (repetitive) calculations to optimize the positions of the centroids
It halts creating and optimizing clusters when either:
- The centroids have stabilized — there is no change in their values because the clustering has been successful.
- The defined number of iterations has been achieved.
Program for K- Means Clustering Algorithm using iris Dataset:
Step 1: Import libraries

First, we will import the libraries needed for our program.
- Clustering of unlabeled data can be performed with the help of sklearn.cluster module. From this module, we can import the KMeans package.
- Pandas for reading and writing spreadsheets
- Numpy for carrying out efficient computations
- Matplotlib for visualization of data
Step 2: Add datasets, column names and plot graph for the dataset
Here is the code for importing the dataset from the location it is stored on your computer to a new variable. “Iris” is the variable name in which we will be loading our required dataset.
The pd.read_csv is used to read the csv file (dataset file). The first line of the above code denotes the format for loading the dataset. We can also import inbuilt datasets using the following code:
Iris = datasets.load_iris()
In order to execute this line, you will have to import the datasets package from sklearn. In order to do that just add the following line above the import statements:
from sklearn import datasets
The next step is to add the column names on which we want to apply clustering. So here we have taken “Sepal Length Cm” and “Petal Length Cm”.
Both these columns are then loaded into X1 and X2 variables respectively. Here, np.array is used so that the columns are stored in an array format which will make it easy for us to perform clustering.
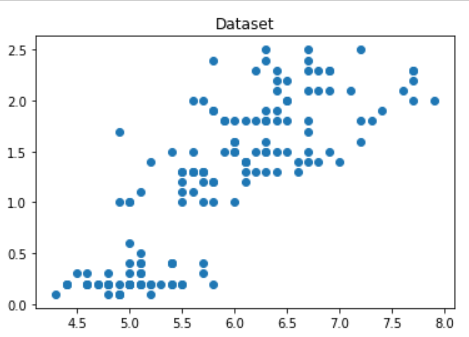
After that plt.scatter(x1,x2) is used to plot the scatter graph for the specified columns. plt.plot() and plt.show() is used to make the graph visible to you.
Step 3: Creating a new plot and data, applying the kmeans inbuilt function and plotting the graph.

In the next step, the numpy zip() method is used to create an iterator that will aggregate elements from two or more iterables. Then those zipped elements are loaded into a variable X. This X is passed in the fit() method.
The colors and markers are used to denote the colors and markers of your data points.
Then we call the KMeans function and pass n_clusters=3 (here, 3 determines the number of clusters you need to be displayed. After that we use the fit() method for training our model. Fitting your model to (i.e. using the .fit() method on) the training data is essentially the training part of the modeling process.
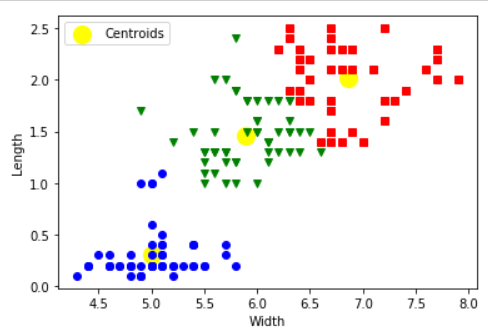
The plt.scatter is used to plot the centroids of the clusters. We pass the kmeans.cluster_centers_ to plot the centroid points on the graph.
The enumerate function allows us to loop over something and have an automatic counter.
The next line plt.plot(x1[i], x2[i], color=colors[l], marker=markers[l]) is used to plot the final graph with centroids and the clusters formed successfully.
Click here to download the Program and Datasets…

